
前回、LVSを利用したwebサーバのロードバランシングをご紹介しましたが
もし仮に、バックエンドのwebサーバの一つがDOWNしていたとしましょう。
生きているwebサーバにバランシングされれば正常にアクセス可能ですが。
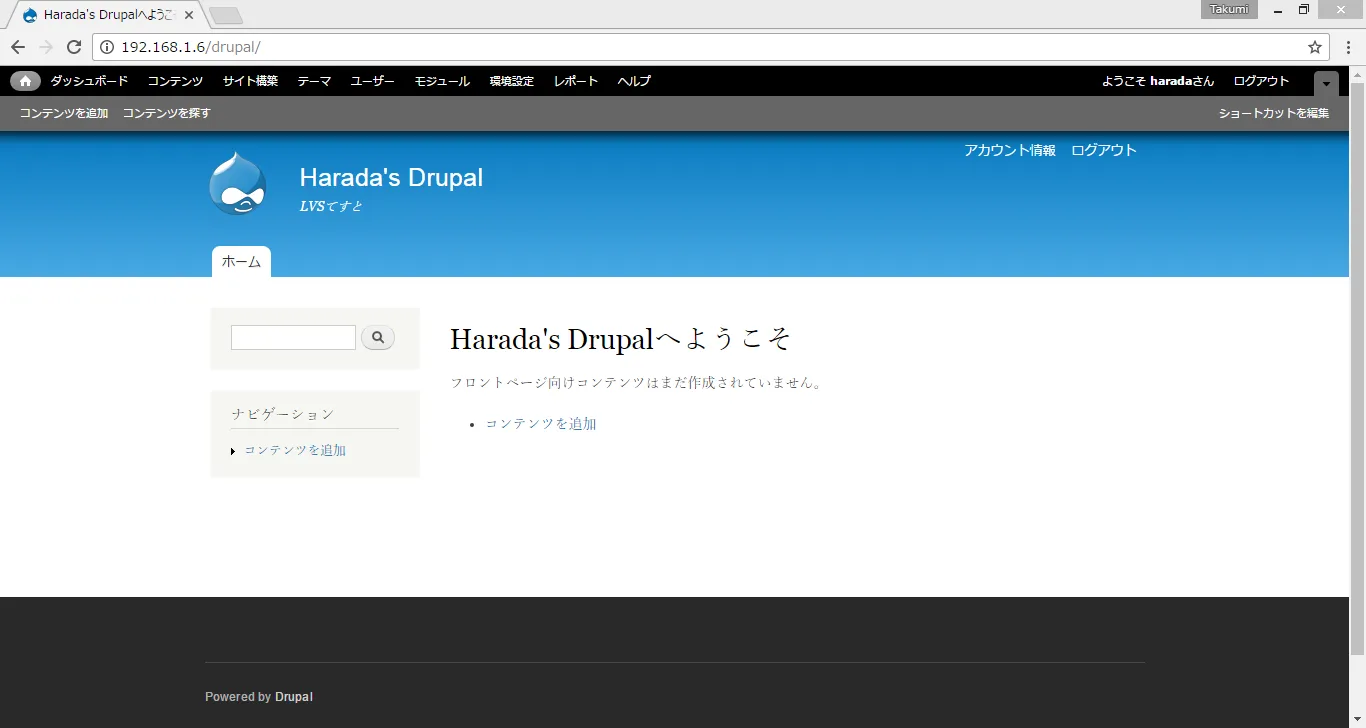
DOWNしているサーバに振り分けられてしまうと、この様に閲覧不可に。
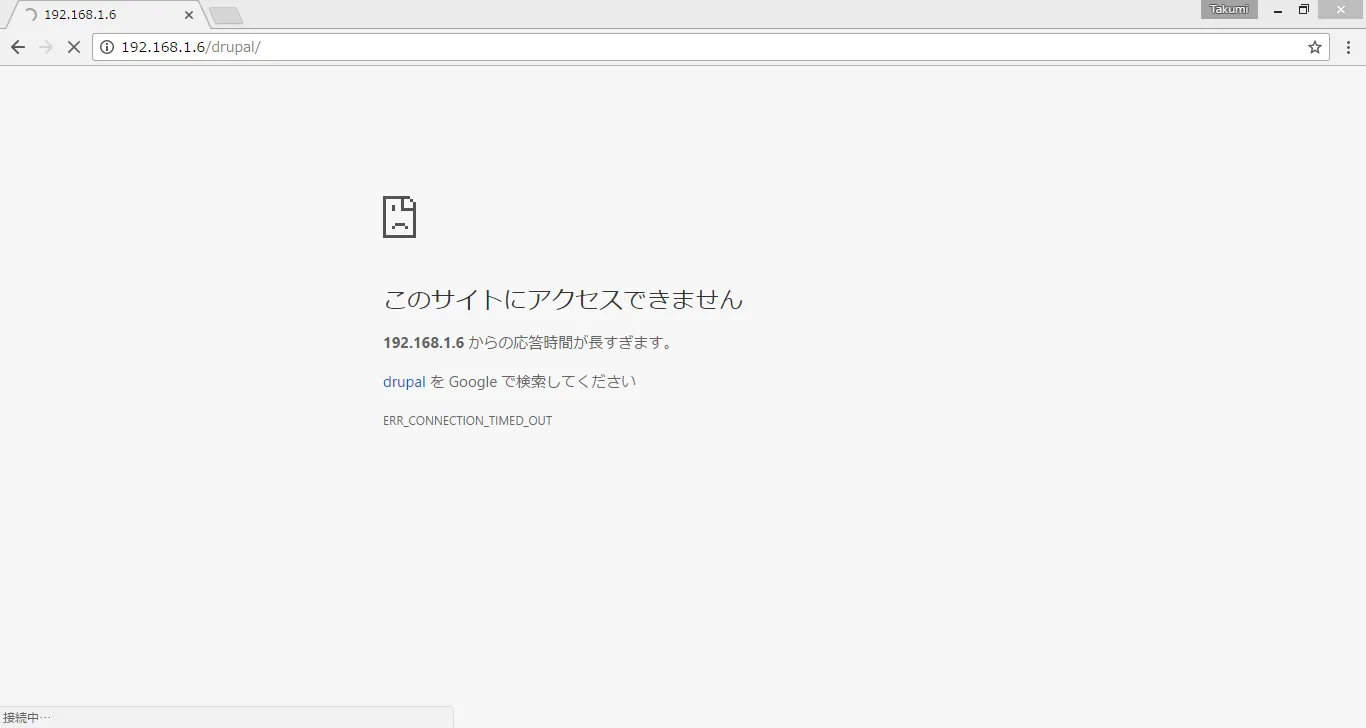
この様な事態を防ぐための機能として、Keepalived があります。
Keepalivedは転送先サービスの死活監視をすることで、
こうした状態を回避し、サービスの冗長化を実現できます。
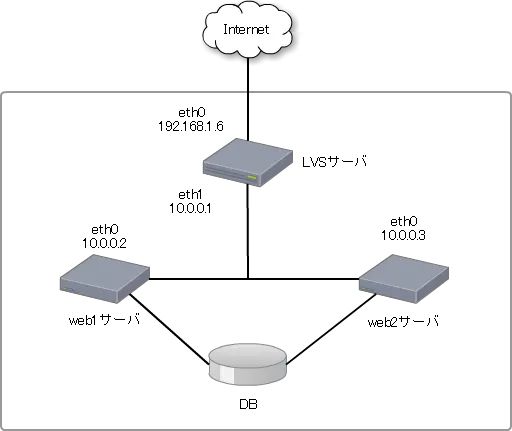
構成環境
keepalived を導入する環境は前回同様、以下の構成となります。
1.LVSの設定をクリア
LVS の設定は Keepalived で制御されるので、まずは ipvsadm の設定をクリアします。
これを忘れると設定が競合して、うまくバランシングされないので注意。
# ipvsadm -C
# /etc/rc.d/init.d/ipvsadm save
ipvsadm: Saving IPVS table to /etc/sysconfig/ipvsadm: [ OK ]
2.keepalivedをインストールする
いつも通り yum でインストールします。
# yum install keepalived
3.Keepalivedの設定を行う
keepalived の設定ファイルを作成します。
分散方式はラウンドロビン、パケット転送は NAT と前回同様にします。
virtual_server 192.168.1.6 80 { # lvsサーバのeth0のIPを指定します。
delay_loop 60 # ヘルスチェックの間隔 [秒]
lvs_sched rr # ロードバランスの方法 (分散方式はround robin)
lvs_method NAT # パケット転送の方法 (NAT)
protocol TCP
# Web 1
real_server 10.0.0.2 80 {
weight 1
inhibit_on_failure # ヘルスチェック失敗時はweightを0にしてバランシングしない。
HTTP_GET {
url {
path /drupal/ # ヘルスチェック用のページ
status_code 200 # ステータスコード
}
connect_timeout 3 # 応答が返ってくるまでのタイムアウト [秒]
}
}
# Web 2
real_server 10.0.0.3 80 {
weight 1
inhibit_on_failure
HTTP_GET {
url {
path /drupal/
status_code 200
}
connect_timeout 3
}
}
}
■ 解説
url ブロック:
url {
path /drupal/ # ヘルスチェック用のページ
status_code 200 # ステータスコード
}
期待する HTTP レスポンスコードは status_code で指定します。
今回の場合、リアルサーバが http://192.168.1.6/drupal/ のリクエストに対して
200 以外 のレスポンスコードを返した場合は、ヘルスチェック失敗となります。
connect_timeout:
connect_timeout 3 # 応答が返ってくるまでのタイムアウト [秒]
ヘルスチェックの HTTP アクセスのタイムアウト秒数を指定します。
HTTP アクセスを始めてからレスポンスを受け取りきるまで、connect_timeout 秒で完了しない場合は
ヘルスチェック失敗となります。
注意点として、connect_timeout のデフォルトは 0 なので、
明示的に指定しないと「0秒でレスポンスを返さないといけない」扱いになります。
そのため connect_timeout は必ず指定 しましょう。
inhibit_on_failure:
inhibit_on_failure # ヘルスチェック失敗時はweightを0にしてバランシングしない。
inhibit_on_failure を指定しているので、
グループから外すときは設定を削除するのではなく weight を 0 にする 挙動になります。ipvsadm -Ln で見たときに、どのリアルサーバが外されているか分かりやすいです。
sorry_server:
sorry_server 192.168.1.6 80
sorry_server は、全てのリアルサーバがダウンした場合 に
パケットが転送されるサーバです。
今回は設定していませんが、実運用では ロードバランサ以外のサーバ を指定した方がよいでしょう。
また、ひとつの real_server と sorry_server という構成にすれば、
アクティブ/バックアップ構成を作ることもできます。
今回の設定内容は最低限のみですが、keepalived の設定は非常に多岐にわたり、
複雑な挙動も設定可能です。ここでは書ききれないので割愛します。
4.keepalivedを起動する
# /etc/rc.d/init.d/keepalived start
Starting keepalived: [ OK ]
自動起動設定:
# chkconfig keepalived on
5.挙動確認
[root@lvs ~]# ipvsadm
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.1.6:http rr
-> 10.0.0.2:http Masq 1 0 0
-> 10.0.0.3:http Masq 1 0 0
weight が 1 になっていれば正常です。
試しに web1 の apache を停止してみます。
[root@web01 ~]# service httpd stop
httpd を停止中: [ OK ]
すると、10.0.0.2 の weight が 0 になったことを確認できます。
[root@lvs ~]# ipvsadm
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.1.6:http rr
-> 10.0.0.2:http Masq 0 0 0
-> 10.0.0.3:http Masq 1 0 0
この状態で lvs の IP にアクセスしても、応答のない web1 にはバランシングされません。
これが keepalived を使用した、バランシング対象サーバのヘルスチェック機能です。
おまけ
10.0.0.1 - - [12/Feb/2017:12:39:08 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:11 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:14 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:17 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:20 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:23 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:26 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:29 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:32 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:35 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:38 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:41 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:44 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:47 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:50 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:53 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:56 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:39:59 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:40:02 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:40:05 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:40:08 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:40:11 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:40:14 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:40:17 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
10.0.0.1 - - [12/Feb/2017:12:40:20 +0900] "GET / HTTP/1.0" 403 4961 "-" "KeepAliveClient"
最初 keepalived のヘルスチェック間隔を 3 秒にしていたのでログが大量に出ました。
lvs の IP アドレスは除外するか、チェック間隔を伸ばした方が良いかもしれません。




