課題としては短めの小ネタ記事になります。
概要
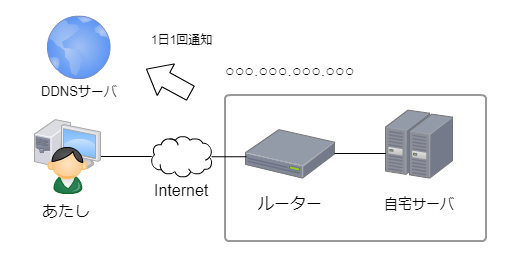
外部から自宅に保管してあるデータを参照したい時のため
自宅サーバはSSHだけ外部に開けています。
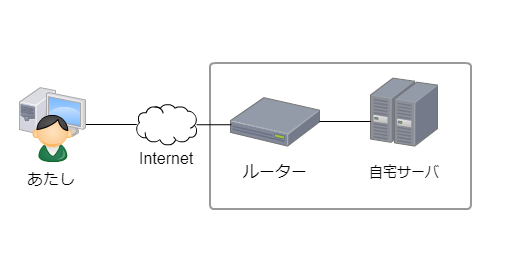
自宅のサーバは、プロバイダから付与されるグローバルIPが1個つきます。
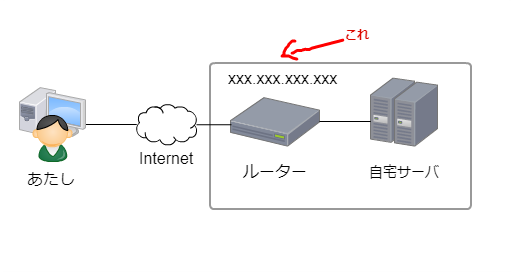
当然固定IPではないので、一定期間が過ぎたり
ルーターが再起動されてしまうと、IPが変わってしまいます。
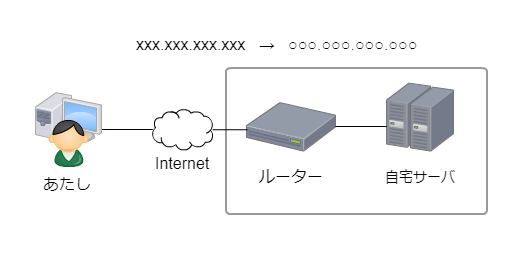
通常グローバルIPが変わる頻度はそう多くないので
自宅サーバからDDNSのサーバに対して1日1回IP通知をしてやれば十分です。
ところが、何かしらの原因で不意にルーターが再起動されてしまった場合
再起動後にグローバルIPが別のものに変わってしまいます。
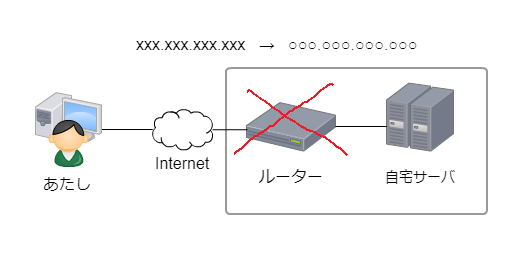
不意の再起動が走った場合、DDNSサーバへの通知は1日1回きりなので
次回の通知まで自宅サーバへはアクセス不可の状態となります。
再起動されたタイミングにもよりますが、
最大で24時間自宅サーバへのアクセス不可が続いてしまうので不便でした。。
そこで考えた仕組み
①自宅にNagiosで監視サーバを立てて、ルータの死活監視を行う。
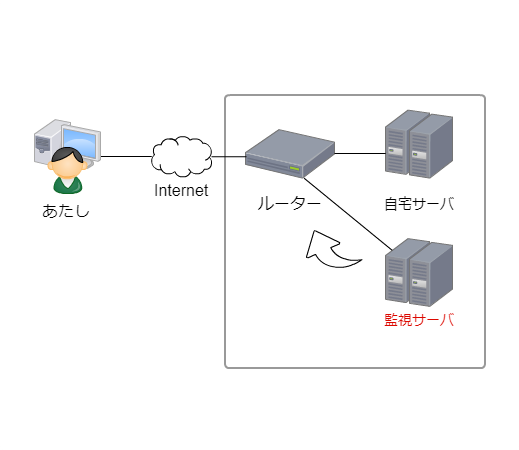
②ルータが再起動された(応答不能になった)時にアラート検知
※外部の出口が死んでいるのでこの時点では通知はされない。
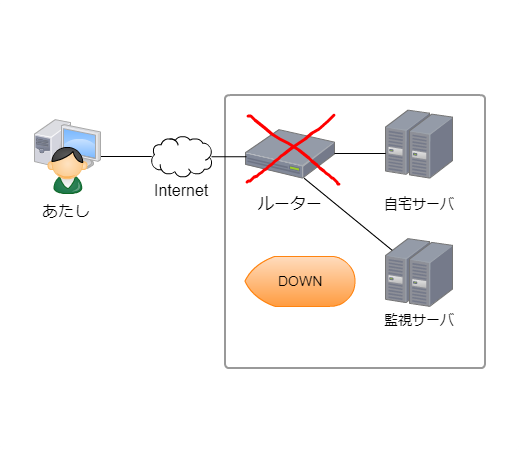
③ルータが再起動された(UP)したタイミングでNagiosのイベハンが発動し
DDNSサーバへ新しいグローバルIPを通知する。
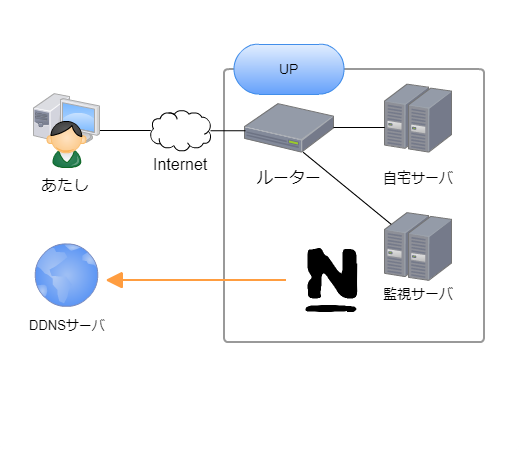
④IP通知が成功したら、Slackでルータが再起動されたメッセージを飛ばす。
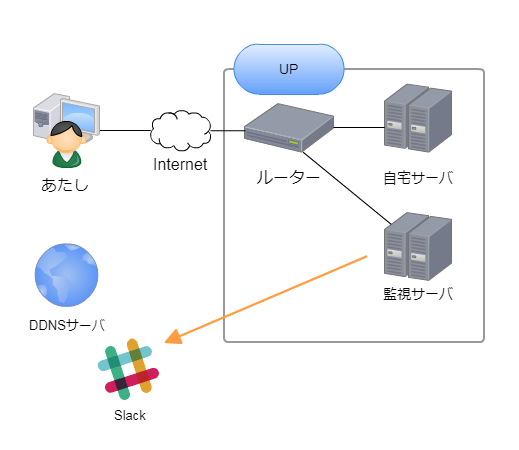
我ながら素晴らしい発想力。

Slack側の準備
長々と概要を説明しましたが、組み込みは殆どないです。
まずはSlackのセットアップから。Slackの登録は以下を参照して下さい。
Slackにメッセージを飛ばす方法ですが
手順としてはIncoming WebHooksの登録だけでOK。
そんな簡単でよいのかと思われますが、とりあえず手順をまとめます。
Incoming WebHooksの登録
slackにログインします。
名前の右側のボタン(?)をクリックして「Configure Integrations」を選択します
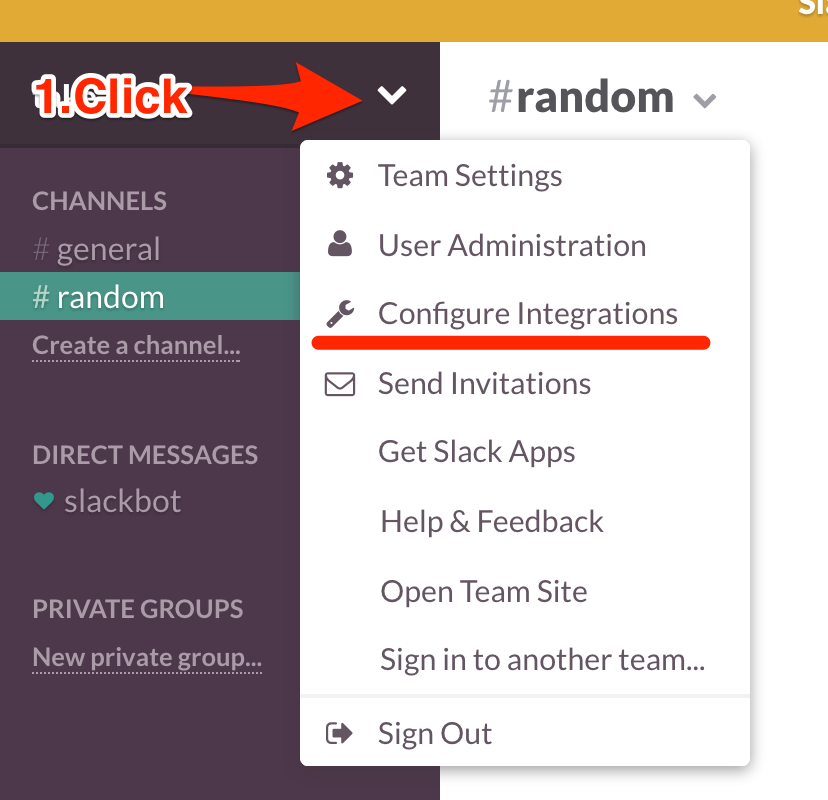
一覧が沢山でてきますが、「Incoming WebHooks」を選択します。
ブラウザの検索を使うと便利です。
「Incoming WebHooks」は、指定されたURLにメッセージを送ると
slack上にそのメッセージが表示されるという機能です。
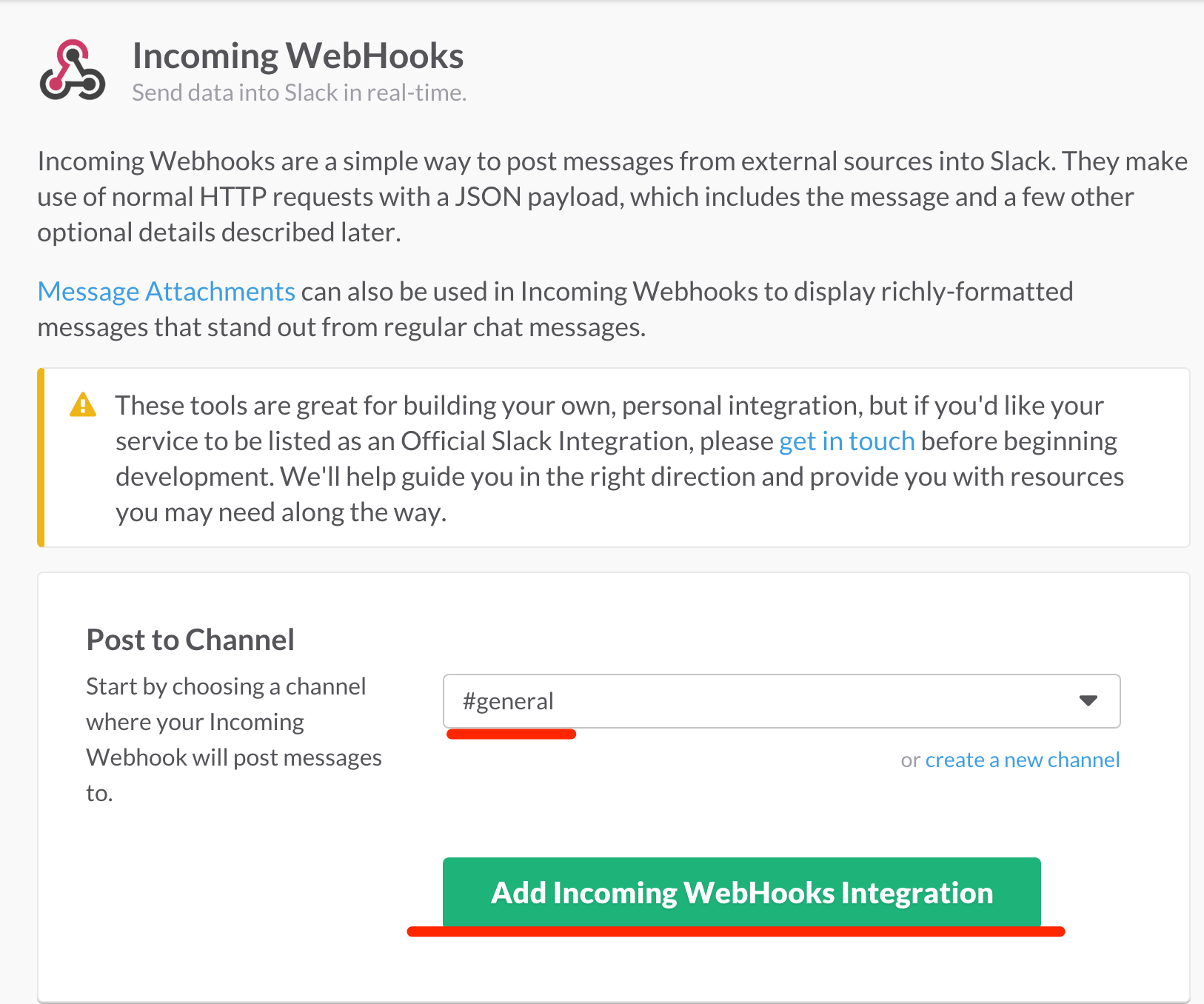
右側の「+Add」ボタンをクリックします。

デフォルトの投稿チャンネルを選択します。
Incoming WebHooks に引数をあたえることで投稿チャンネルは変更できます。
個人的にはテスト等のチャンネルをつくっておいて、設定することをお勧めしますが、
この例では#generalを設定しています。
設定後、「Add Incoming Webhooks Integration」ボタンが有効になるのでクリックします。
次の画面で「Setup Instructions」というタブが現れます。
ここに送信用のURLが表示されるのですが、実はExampleが既に用意されてます。
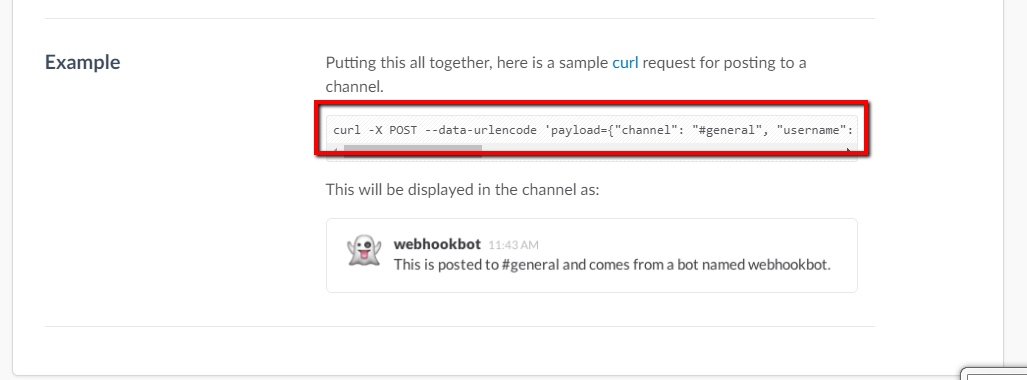
表示されてるcurlコマンドをシェル上で打つと
下に表示されている様な感じでgeneralチャンネルにメッセージが飛びます。
なんて親切なんでしょう。
メッセージの内容は適宜改変して、スクリプトに直接組み込んじゃうので
Slack側の準備はこれにて終了。ね、簡単でしょ?
イベハン用のスクリプトを作成する
ここまで来たら8割は終わりだと思います。
イベハン用のスクリプトはこんな感じで作成しました。
# cat NTT_event_hundler.sh
#!/bin/bash
# $1=$SERVICESTATE$
# $2=$SERVICESTATETYPE$
case "$1" in
OK)
case "$2" in
HARD)
curl http://ipv4.mydns.jp/login.html > /dev/null
curl -X POST --data-urlencode 'payload={"channel": "#general", "text": "PR-400MIが再起動されました。DDNSを再通知します。"}' https://hooks.slack.com/services/[文字列]
exit
;;
*)
;;
esac
;;
*)
;;
esac
exit
Nagiosのcfgは以下の形で。
## Event Handler
define command {
command_name NTT_restart
command_line $USER5$/NTT_event_hundler.sh $SERVICESTATE$ $SERVICESTATETYPE$
}
スクリプト自体は単純で、アラートがOKになった且つHARD検知になれば動くというもの。
それ以外の場合(CRITICAL、WARNING検知時)は、何もしません。
リカバリー時の挙動として、まずDDNSへ通知が行われ
Slackの #generalチャンネルに「ルーターが再起動されました。DDNSを再通知します。」としてメッセージを飛ばしています。
以下メッセージテスト例。

今回の躓きポイント
当初、ホスト監視にイベハンを設定していたのですが(↓こんな感じ)
# NTT_router
define host{
use dummy-server
host_name NTT_router
alias NTT_router
event_handler NTT_restart
address 192.168.1.1
}
実はホスト監視だとSERVICESTATE、SERVICESTATETYPEに変数が書き込まれず
アラートを検知してもイベハンのスクリプトが動かないという事が発覚しました。(イベハン自体は動く)
解決策として、監視項目にPING監視を追加して
そっちにイベハンを設定する方法にしました。
### gaibu
define service{
use gaibu
host_name NTT_router
service_description PING
event_handler NTT_restart
normal_check_interval 1
retry_check_interval 1
max_check_attempts 1
check_command check-host-alive
}
これできちんとスクリプトが動いてくれました。
これが分かるまで半日かかったのは秘密。
なお、Slackのgeneralチャンネルは一般公開されているので
プライベートチャンネルを利用するとよいかと思います。



![[WIP]Seleniumを使って遷移監視ができるか検証してみた](/content/images/size/w600/2023/11/----------1-.png)
![[WIP]Windows Server 2016を使ってHyper-Vレプリケーション設定](/content/images/size/w600/2023/11/----------2-.png)